学习分布式系统要先了解该系统的整体架构,各个组件作用功能,运行时态的各个组件间互动的关系,核心主逻辑的在各个组件的调用逻辑。整体架构把握后,然后再看各个组件具体工作原理,再进一步看源码了解细节。
《分布式系统原理介绍》第一章
分布式系统模型:
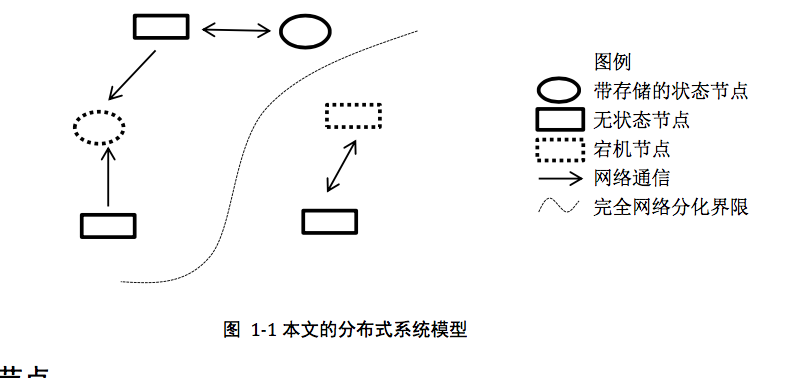
异常是常态:分布式系统核心问题之一就是处理各种异常(failure)情况。
TCP 协议保证了 TCP 协议 栈之间的可靠的传输,但无法保证两个上层应用之间的可靠通信,往往应用间需要确认消息。(使用RPC就可以在应用层确认消息,某种程度算是应用层的可靠通信)
- 题外话:应用程序调用接口保存数据,返回成功也不一定意味着真实落盘,因为通常为了性能,不使用直写模式,数据只会写入操作系统内核缓存区就返回成功了,尤其使用分布式文件系统,IO路径更长。
由于网络异常的存在,分布式系统中请求结果存在“三态”的概念:成功、 失败、 超时(未 知)。对于超时的请求,我们无法获知该 请求是否被节点 B 成功执行了,因此要特殊处理,一种简单处理方式,就是调用接口要幂等性(分布式系统设计中,幂等性很重要,可以保证系统状态的正确性)。
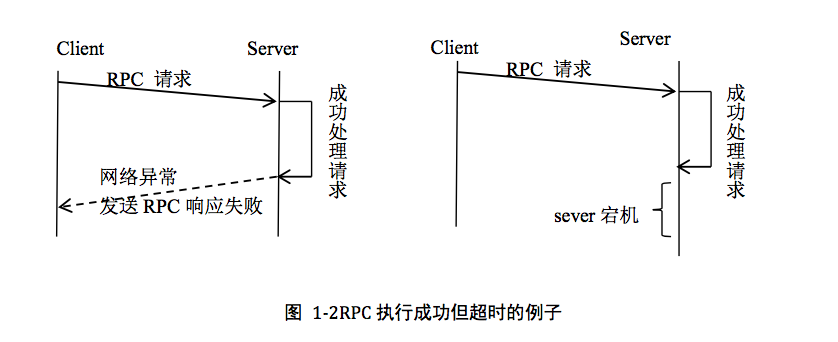
在工程实践中,大量异常情况是无法预先可知的:例如,磁盘故障会导致 IO 操作缓慢,从而有可能使得进程运行速度非常慢,进而对整个系统会造成影响。又例如网络不稳定时也会引起“半死不活”异常,例如网络发生严重 拥塞时约等于网络不通,过一会儿又恢复,恢复后又拥塞,如此交替。
被大量工程实践所检验过的异常处理黄金原则是:任何在设计阶段考虑到的异常情况一定会在 系统实际运行中发生,但在系统实际运行遇到的异常却很有可能在设计时未能考虑,所以,除非需 求指标允许,在系统设计时不能放过任何异常情况。
工程中常常容易出问题的一种思路是认为某种异常出现的概率非常小以至于可以忽略不计。(墨菲定律:一、任何事都没有表面看起来那么简单;二、所有的事都会比你预计的时间长;三、会出错的事总会出错;
四、如果你担心某种情况发生,那么它就更有可能发生。)
- 衡量分布式系统的指标
- 可扩展性(scalability) : 指分布式系统通过扩展集群机器规模 高系统性能(吞吐、延迟、 并发)、存储容量、计算能力的特性。可扩展性是分布式系统的特有性质。分布式系统的设计初衷就 是利用集群多机的能力处理单机无法解决的问题.
- 可用性:可用性是分布式的重要指标,衡量了系统的鲁棒性,是系统容错能力的体现。
- 性能指标:系统的吞吐能力,QPS(query per second),系统的响应延迟。追求高吞吐的系统,往往很难做到低延迟;系统平均响应时间较长时,也很难提高QPS。(参考:吞吐量(TPS)、QPS、并发数、响应时间(RT)概念和系统吞吐量(TPS)、用户并发量、性能测试概念和公式)
- 一致性: 分布式系统为了高可用性,总是不可避免的使用副本的冗余机制,从而引发副本一致性的问题。
Introduction to Distributed System Design
Introduction to Distributed System Design
有关分布式计算的几个谬论: 网络是可靠的。延迟为零。带宽是无限的。网络是安全的。拓扑不会改变。肯定有一个管理员。传输的代价为零。网络是同质的。
常见异常:
- Halting failures: A component simply stops. There is no way to detect the failure except by timeout: it either stops sending “I’m alive” (heartbeat) messages or fails to respond to requests. Your computer freezing is a halting failure.
- Fail-stop: A halting failure with some kind of notification to other components. A network file server telling its clients it is about to go down is a fail-stop.
Omission failures: Failure to send/receive messages primarily due to lack of buffering space, which causes a message to be discarded with no notification to either the sender or receiver. This can happen when routers become overloaded. - Network failures: A network link breaks.
Network partition failure: A network fragments into two or more disjoint sub-networks within which messages can be sent, but between which messages are lost. This can occur due to a network failure. - Timing failures: A temporal property of the system is violated. For example, clocks on different computers which are used to coordinate processes are not synchronized; when a message is delayed longer than a threshold period, etc.
- Byzantine failures: This captures several types of faulty behaviors including data corruption or loss, failures caused by malicious programs, etc.
分布式系统特性:
- Fault-Tolerant: It can recover from component failures without performing incorrect actions.
- Highly Available: It can restore operations, permitting it to resume providing services even when some components have failed.
- Recoverable: Failed components can restart themselves and rejoin the system, after the cause of failure has been repaired.
- Consistent: The system can coordinate actions by multiple components often in the presence of concurrency and failure. This underlies the ability of a distributed system to act like a non-distributed system.
- Scalable: It can operate correctly even as some aspect of the system is scaled to a larger size. For example, we might increase the size of the network on which the system is running. This increases the frequency of network outages and could degrade a “non-scalable” system. Similarly, we might increase the number of users or servers, or overall load on the system. In a scalable system, this should not have a significant effect.
- Predictable Performance: The ability to provide desired responsiveness in a timely manner.
- Secure: The system authenticates access to data and services
很难设计出包含全部特性的分布式系统,因此在设计系统要根据具体需求做权衡了。尤其在数据类分布式系统,经典就是CAP,BASE,ACID理论了。
